AI Development
A Deep Dive into BERT: Understanding the Transformer Model
 Updated 02 Aug 2024
Updated 02 Aug 2024

The realm of Natural Language Processing or NLP has experienced a dramatic alteration with the introduction of the BERT language model(Bidirectional Encoder Representations from Transformers). This isn’t just another technical term; the BERT language model represents a groundbreaking model that fundamentally changes how machines interpret and interact with human language. But what exactly makes BERT so powerful? Let’s delve deeper into how BERT works and unveil the magic behind this revolutionary NLP marvel.
The Bottleneck of Traditional NLP Models
Imagine a machine trying to decipher a sentence. Traditional NLP models, like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Units), functioned like someone reading a book one word at a time. This linear approach posed a significant challenge, which is capturing context. Since these models processed information sequentially, they often struggled to grasp the crucial relationships between words and their surrounding context. This limitation resulted in misinterpretations, like mistaking “bank” for the riverside in the sentence “The bank can guarantee deposits will not be lost.”
The Transformer Revolution: The BERT Model Architecture
A pivotal moment arrived in 2017 with the innovative introduction of the Transformer architecture by Vaswani et al. This architecture marked a paradigm shift in NLP. Unlike traditional models, the Transformer doesn’t get stuck in a linear rut. Instead, it leverages a powerful mechanism called “self-attention.” This allows the model to process all words in a sentence simultaneously, akin to giving the machine a comprehensive map of the entire sentence structure. With self-attention, the Transformer can analyze the relationships between each word and its neighbors, enabling it to grasp the bigger picture and derive a more nuanced understanding of the text. This breakthrough led to the development of the BERT model architecture, enhancing how AI Development Services utilize contextual information. Do you know that it is estimated that BERT enhances Google’s understanding of approximately 10% of U.S.-based English language Google search queries?
Unveiling BERT Language Model Superpowers: Bidirectionality and Pre-training
BERT language model takes the Transformer architecture a step further by introducing the concept of bidirectionality. Unlike us reading a sentence from left to right, traditional NLP models were limited to a unidirectional flow of information. BERT breaks free from this constraint. It can process text in both directions, just like we do as humans. This allows BERT to consider the entire context around a word, not just what precedes or follows it. Imagine reading the sentence “The quick brown fox jumps over the lazy dog” from both ends. By considering “lazy dog” while processing “fox,” BERT can definitively determine that “fox” refers to the animal and not a shade of color.
Furthermore, BERT’s power lies not only in its architecture but also in its pre-training process. Before being fine-tuned for specific tasks, BERT is exposed to a massive dataset of text and trained on two unsupervised tasks:
1. Masked Language Modeling (MLM)
Imagine hiding random words in a sentence and asking someone to guess them. That’s essentially what MLM does. By training on massive amounts of masked text data, the BERT language model learns to predict the missing words based on the surrounding context. This strengthens its understanding of complex language patterns and relationships between words. Before feeding word sequences into BERT, 15% of the words in every sequence are replaced with a [MASK] token.
2. Next Sentence Prediction (NSP)
This task focuses on teaching BERT how to understand the connection between sentences. The model is offered with pairs of sentences and has to predict if the second sentence logically follows the first. This process hones BERT’s ability to grasp the flow of ideas and the relationships between different parts of a text.
Unpacking BERT Model Architecture
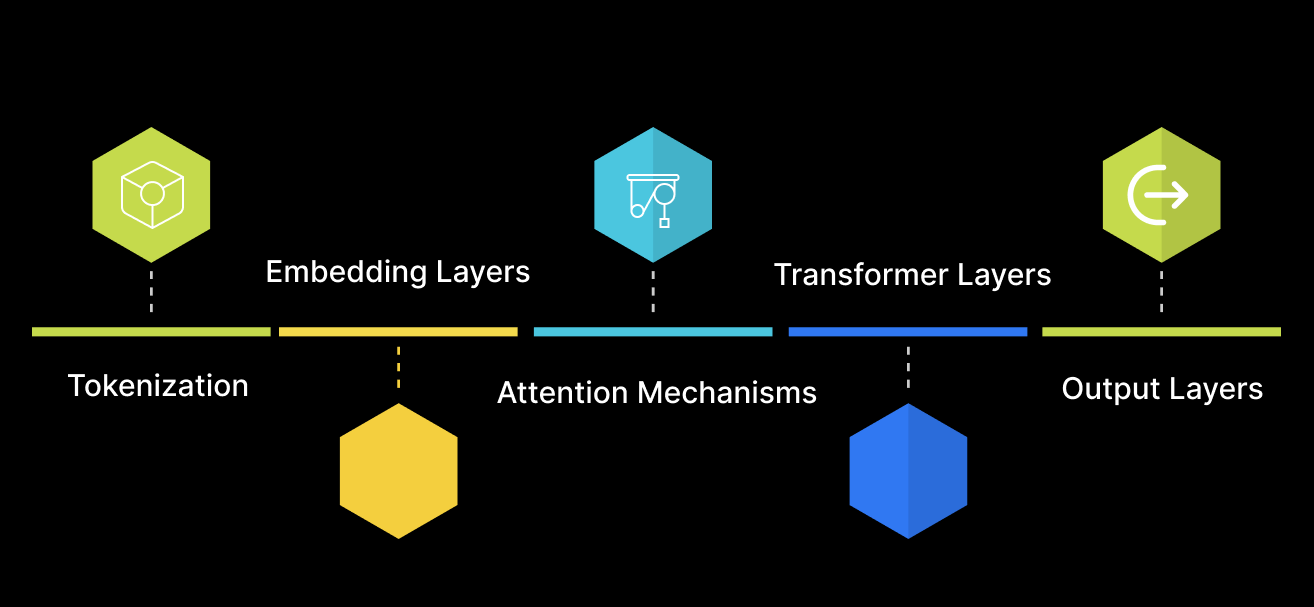
1. Tokenization
The BERT language modelbegins by tokenizing the input text. It uses WordPiece tokenization, breaking down words into smaller subwords or characters, which helps manage out-of-vocabulary words and improve model performance. For example, the word “unhappiness” might be broken into “un,” “happi,” and “ness.”
2. Embedding Layers
After tokenization, BERT converts tokens into embeddings. These embeddings are a combination of:
- Token embeddings: Represent individual tokens.
- Segment embeddings: Distinguish between different sentences.
- Positional embeddings: Encode the position of tokens in a sentence, enabling the model to understand word order.
3. Attention Mechanisms
The core of BERT’s power lies in its attention mechanisms. The self-attention layers allow BERT to weigh the importance of each word concerning all other words in the sentence. This enables the model to capture nuanced meanings and dependencies. For instance, in the sentence “The bank can guarantee deposits will not be lost,” the word “bank” could mean a financial institution or the side of a river. Self-attention helps BERT determine the correct meaning from the context.
4. Transformer Layers
BERT consists of multiple Transformer layers, each comprising self-attention and feedforward neural networks. These layers process the embeddings in parallel, enabling efficient and effective context understanding. Each Transformer layer refines the input representations, making them richer and more contextually aware.
5. Output Layers
Finally, BERT’s output layers generate predictions for various NLP tasks, such as question answering, text classification, and named entity recognition. The model can be fine-tuned to excel in specific applications by adding task-specific layers on top of the pre-trained BERT model architecture.
How BERT Works
BERT model architecture works by employing the Transformer architecture’s bidirectional nature, allowing it to process text both forward and backward simultaneously. It starts with tokenizing the input text into subwords using WordPiece tokenization, then converting these tokens into embeddings, that incorporate token, segment, and positional information. These embeddings are fed through multiple layers of self-attention and feedforward neural networks. The self-attention mechanism helps the BERT language model weigh the significance of each word relative to all others in the sentence, capturing nuanced meanings and contextual relationships. This produces rich, contextually aware word representations, which can then be fine-tuned for various NLP tasks such as question answering, text classification, and named entity recognition. AI Development Services can harness the power of BERT model architecture to drive innovative solutions in these fields. By leveraging How BERT works, these services can create advanced applications that understand and process natural language with unprecedented accuracy.
From Pre-Training to Action: How BERT Language Model Performs NLP Tasks
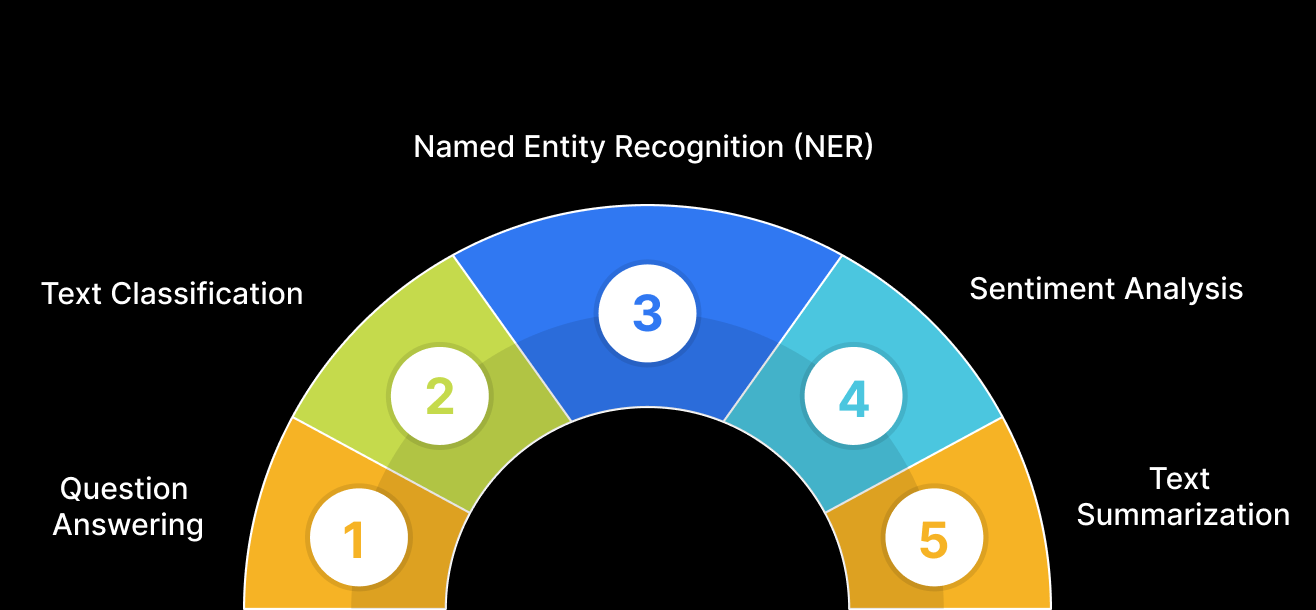
Once pre-trained, BERT model architecture is like a talented musician who’s mastered the fundamentals. But to truly shine, it needs to be fine-tuned for a specific instrument – the NLP task at hand. This fine-tuning involves training the model on labeled data relevant to the desired task. BERT has been successfully applied to over 11 NLP tasks, including sentiment analysis, question answering, and named entity recognition. Here’s a breakdown of How BERT works in tackling various NLP challenges:
1. Question Answering
Imagine you have a complex question about a lengthy passage. BERT can be your guide. By considering the entire context of the passage and the relationships between words, BERT can pinpoint the most relevant information to answer your query accurately. It’s like BERT is reading the passage and highlighting the key points that directly address your question. This makes BERT a powerful tool for applications like search engines, where users often have complex information needs.
2. Text Classification
In today’s world, we’re bombarded with text data from the news articles and social media posts to product reviews and customer feedback. BERT excels at classifying this data. Whether it’s determining the sentiment of a review (positive, negative, or neutral) or classifying news articles into different categories (sports, politics, etc.), BERT’s ability to understand the nuances of language allows it to categorize text data with high accuracy. Imagine a system that automatically sorts through your inbox, flagging urgent emails and filtering out spam – that’s the kind of power BERT brings to text classification tasks.
3. Named Entity Recognition (NER)
Have you ever come across a document filled with names, locations, and organizations? It can be a challenge to keep track of them all. But BERT can help. Recognizing and classifying important entities like people, organizations, locations, and monetary values is another area where BERT shines. By understanding the context and relationships between words, BERT can effectively identify these entities within a text. Imagine a system that can automatically extract key players and locations from a news article – that’s the kind of power BERT brings to NER tasks.
4. Sentiment Analysis
Not all text is created equal. Sometimes, we want to understand the underlying emotion or opinion conveyed in a piece of writing. BERT model architecture is adept at sentiment analysis. It can analyze text and determine whether it expresses positive, negative, or neutral sentiments. This is valuable for tasks like gauging customer satisfaction in reviews or understanding the overall tone of social media conversations. Imagine a system that can analyze customer feedback and identify areas where improvement is needed – that’s the kind of power BERT brings to sentiment analysis tasks.
5. Text Summarization
In our fast-paced world, time is a precious commodity. But information overload is a constant struggle. BERT can help us cut through the noise by generating concise summaries of lengthy text passages. By leveraging its understanding of context and relationships between words, BERT can identify the key points and create summaries that capture the principle of the original text. Imagine a system that can automatically summarize lengthy news articles or research papers – that’s the kind of power BERT brings to text summarization tasks.
BERT Model Architecture’s Impact on NLP
Since its introduction, the BERT language model has set new benchmarks across various NLP tasks, outperforming previous models by a significant margin. Its ability to understand context and capture subtle nuances has made it the go-to model for researchers and practitioners alike. How BERT works has been demonstrated through its integration into numerous applications, including:
1. Search Engines
BERT helps improve the relevance of search results by learning the context of user queries more accurately.
2. Chatbots
BERT enhances chatbot performance, enabling more natural and context-aware interactions.
3. Sentiment Analysis
BERT improves the accuracy of sentiment analysis tools by capturing the nuances of human language.
BERT’s versatility and robustness have paved the way for more advanced models like GPT-3 and T5, further pushing the boundaries of what’s possible in NLP. These models build on BERT’s foundations, incorporating larger datasets, more parameters, and improved architectures to achieve even greater performance.
Challenges and Future Directions
Despite its success, BERT is not without challenges. Some of the key issues include:
1. Computational Resources
Training and fine-tuning BERT model architecture requires significant computational power, making it inaccessible for some organizations and researchers. AI Development Services can help bridge this gap by providing scalable solutions.
2. Interpretability
BERT’s complexity makes it difficult to interpret its inner workings, posing challenges for debugging and understanding model decisions.
3. Bias
Like all AI models, BERT can inherit biases present in the training data, as a result producing biased predictions.
Future research aims to address these challenges by developing more efficient models, improving interpretability, and mitigating biases. Additionally, researchers are exploring ways to make NLP models more energy-efficient and environmentally friendly.
A Future of Seamless Communication: BERT’s Model Architecture and Beyond
BERT’s language model has set a new benchmark in NLP, ushering in a pivotal moment in research. It addresses key challenges like efficiency, interpretability, and bias, positioning BERT’s model architecture as a foundational element for future advancements. This evolution promises a future where AI assistants better understand context and language learning apps offer personalized support, showcasing the transformative impact of How BERT works.
Looking ahead, BERT’s language model is poised to revolutionize fields such as education, healthcare, and customer service. Imagine a world where language barriers are eliminated, and AI-powered tutors customize lessons to individual needs. AI Development Services will be crucial in bringing these possibilities to life. The advancements inspired by BERT model architecture promise to redefine our interaction with technology and each other on a global scale.
For businesses looking to leverage the power of the BERT language model and other cutting-edge technologies, Q3 Technologies stands out as a leader in providing innovative solutions. With expertise in AI Development Services, machine learning, and NLP, we can help you integrate advanced models like BERT model architecture into your business processes, enhancing efficiency, accuracy, and customer satisfaction. Whether you need custom software development, IT consulting, or AI-driven solutions, at Q3 Technologies we offer inclusive services designed to meet your specific needs. Partner with us to transform your business and stay ahead in the swiftly evolving digital landscape.

Table of content
- The Bottleneck of Traditional NLP Models
- The Transformer Revolution: The BERT Model Architecture
- Unveiling BERT Language Model Superpowers: Bidirectionality and Pre-training
- Unpacking BERT Model Architecture
- How BERT Works
- From Pre-Training to Action: How BERT Language Model Performs NLP Tasks
- BERT model Architecture’s Impact on NLP
- Challenges and Future Directions
- A Future of Seamless Communication: BERT’s Model Architecture and Beyond
Looking for a Trusted Technology Partner?
From AI development and chatbot solutions to enterprise software and mobile apps, Q3 Technologies delivers end-to-end technology services..


