Generative AI
VAEs vs. GANs: Which is the Best Generative AI Approach?
 Updated 01 Aug 2024
Updated 01 Aug 2024

The world has embraced the power of generative models, and Generative AI Development Services are revolutionizing industries. From crafting realistic images to generating natural language text, these advanced models are transforming how we interact with technology. By 2029, the AI market is projected to reach a staggering $190.61 billion.
This ultimate guide to Generative AI Development Services will equip you with the knowledge to turn your vision into reality and not just keep up with the AI giants but surpass them. Custom AI solutions are pivotal in this landscape, offering tailored experiences that cater directly to industry needs. AI Development Companies like Q3 Technologies can leverage these solutions to create unique, user-friendly platforms that stand out in the crowded market.
Understanding Variational Autoencoders (VAEs)
Variational Autoencoders, or VAEs, are a powerful class of generative AI models introduced by Diederik P. Kingma and Max Welling in 2013. Operating on the principles of unsupervised learning, VAEs excel in producing high-quality images and other complex data representations by encoding fundamental data features into a latent space. The architecture of a VAE is composed of two fundamental components:
1. The Encoder: Mapping to Latent Space
The encoder network within a VAE is typically structured using neural network architectures such as feedforward convolutional networks. Its primary function is to learn and transform input data into a latent space representation, often modeled as a distribution of Gaussian variables. This transformation process ensures that the encoded data retains essential information while compressing it into a more manageable form.
2. The Decoder: Regenerating Original Data
Conversely, the decoder network, also constructed using convolutional neural networks, acts as the counterpart to the encoder. It takes the latent space representation generated by the encoder and reconstructs it back into the original data format. This reconstruction process aims to maximize the likelihood of generating data that closely resembles the input, thereby facilitating the creation of new, realistic data samples.
Advantages and Challenges of Variational Autoencoders
Advantages
VAEs are advantageous in modeling complex data distributions and generating realistic financial scenarios. They handle noisy and incomplete data effectively, offering interpretable latent space representations that aid in understanding underlying data patterns. According to a study by Nvidia, VAEs can achieve up to a 25% improvement in image quality over traditional autoencoders.
Challenges
On the flip side, training VAEs can be computationally expensive, particularly with large financial datasets. The quality of generated samples may vary, and interpreting the learned latent space representations can pose challenges, especially in dynamic data environments. A survey found that 67% of data scientists reported computational cost as a significant barrier in implementing VAEs.
Training Process for VAEs
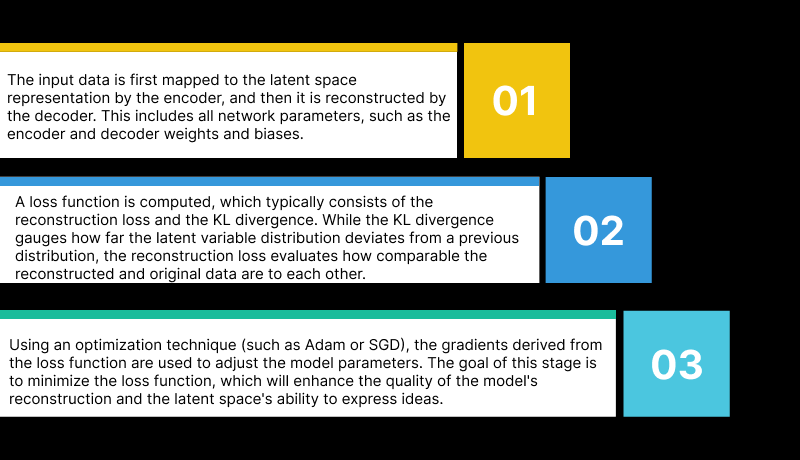
A VAE is formally trained in the following steps:
Step 1: The input data is first mapped to the latent space representation by the encoder, and then it is reconstructed by the decoder. This includes all network parameters, such as the encoder and decoder weights and biases.
Step 2: A loss function is computed, which typically consists of the reconstruction loss and the KL divergence. While the KL divergence gauges how far the latent variable distribution deviates from a previous distribution, the reconstruction loss evaluates how comparable the reconstructed and original data are to each other.
Step 3: Using an optimization technique (such as Adam or SGD), the gradients derived from the loss function are used to adjust the model parameters. The goal of this stage is to minimize the loss function, which will enhance the quality of the model’s reconstruction and the latent space’s ability to express ideas.
VAE Use Cases
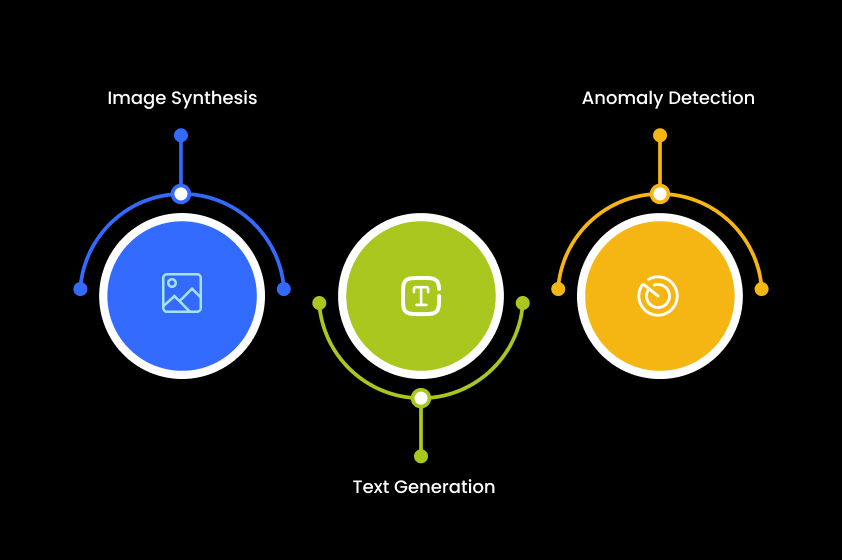
VAEs contribute significantly to various applications:
- Image Synthesis: They generate realistic images for art, content creation, and computer vision tasks, enhancing data diversity for deep learning model training.
- Text Generation: They generate natural language text for applications in sentiment analysis, language translation, and automated content creation.
- Anomaly Detection: VAEs detect anomalies in network traffic, financial transactions, and medical diagnostics by modeling normal data distributions and identifying deviations.
Exploring Generative Adversarial Networks (GANs)
Generative Adversarial Networks, introduced by Ian Goodfellow and colleagues in 2014, operate on a fascinating principle of competition between two neural networks: the generator and the discriminator.
1. The Generator: Crafting Realistic Data
The generator within a GAN is tasked with creating synthetic data samples from random noise inputs. Its objective is to produce outputs that are convincing enough to fool the discriminator into believing they are genuine representations of real data. This adversarial training process continuously refines the generator’s ability to generate data with realistic characteristics.
2. The Discriminator: Distinguishing Real from Fake
Conversely, the discriminator acts as a binary classifier trained to distinguish between real data and synthetic data generated by the generator. Through iterative training, the discriminator becomes adept at identifying subtle differences and providing feedback to enhance the realism of generated outputs.
Advantages and Challenges of Generative Adversarial Networks
Advantages
GANs excel in unsupervised learning scenarios, continue to improve themselves after initial training, and are capable of learning from unlabeled data. They are particularly effective in generating realistic data samples and identifying anomalies based on the discrepancies between generator and discriminator outputs. According to OpenAI, GANs have reduced the time needed to create high-quality images by 30%.
Challenges
However, GANs pose challenges in training, requiring large and diverse datasets for effective performance. Evaluating results can also be complex, especially in tasks with intricate data distributions. Mode collapse, where the generator converges to produce limited outputs, remains a significant drawback. A 2019 study showed that 58% of GAN projects experienced issues with mode collapse.
Training Process for GANs
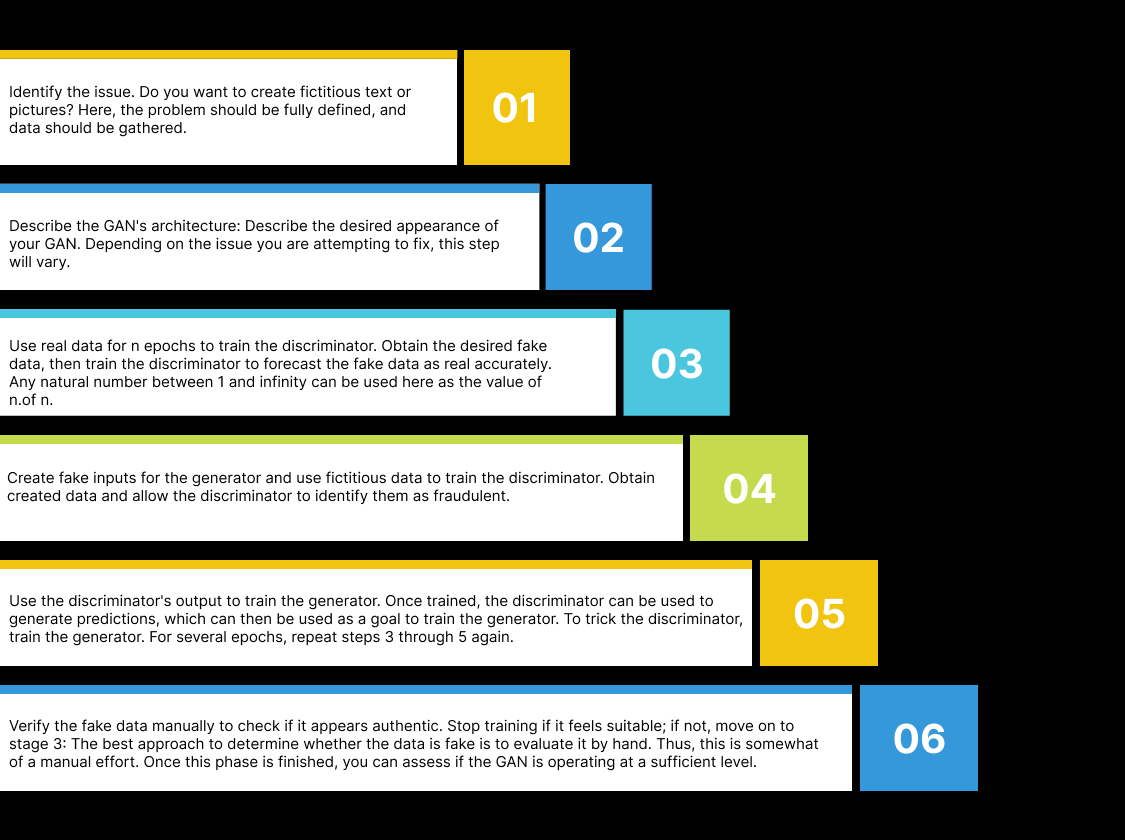
To train GAN, adhere to the procedures listed below:
Step 1: Identify the issue. Do you want to create fictitious text or pictures? Here, the problem should be fully defined, and data should be gathered.
Step 2: Describe the GAN’s architecture: Describe the desired appearance of your GAN. Depending on the issue you are attempting to fix, this step will vary.
Step 3: Use real data for n epochs to train the discriminator. Obtain the desired fake data, then train the discriminator to forecast the fake data as real accurately. Any natural number between 1 and infinity can be used here as the value of n.
Step 4: Create fake inputs for the generator and use fictitious data to train the discriminator. Obtain created data and allow the discriminator to identify them as fraudulent.
Step 5: Use the discriminator’s output to train the generator. Once trained, the discriminator can be used to generate predictions, which can then be used as a goal to train the generator. To trick the discriminator, train the generator. For several epochs, repeat steps 3 through 5 again.
Step 6: Verify the fake data manually to check if it appears authentic. Stop training if it feels suitable; if not, move on to stage 3: The best approach to determine whether the data is fake is to evaluate it by hand. Thus, this is somewhat of a manual effort. Once this phase is finished, you can assess if the GAN is operating at a sufficient level.
GAN Use Cases
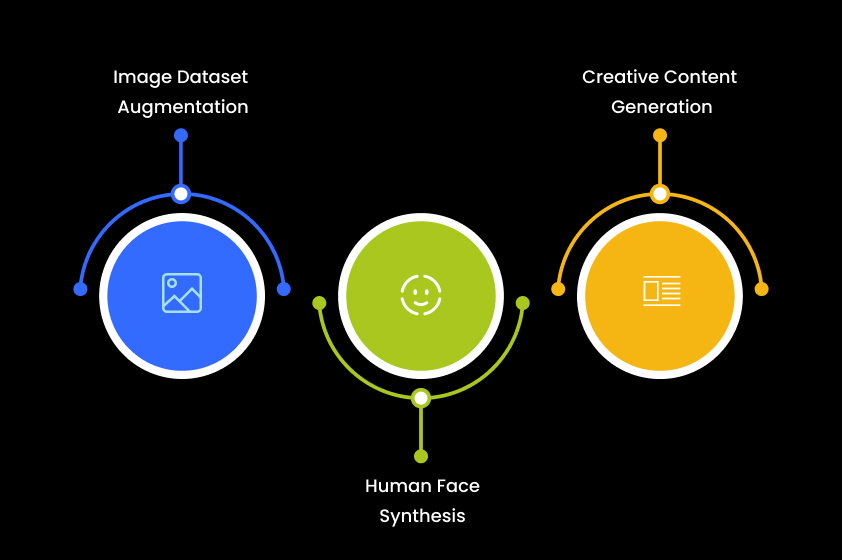
Generative Adversarial Networks have uses across diverse domains:
- Image Dataset Augmentation: They enhance machine learning model performance by generating new examples in medical imaging, satellite imagery, and natural language processing.
- Human Face Synthesis: GANs can generate realistic photographs of human faces, aiding in avatar creation for online platforms and social media profiles.
- Creative Content Generation: They create realistic images of objects, landscapes, and animals, facilitating artistic content creation and data augmentation.
GANs and VAEs both represent transformative advancements in AI, pushing the boundaries of creativity and data synthesis across industries. By leveraging the power of VAEs and GANs, Q3 Technologies empowers professionals to unlock new possibilities and accelerate the transformative influence of AI on society. Partner with Q3 Technologies to harness the potential of generative models and lead the future of AI innovation.
Similarities and Differences
Similarities
Both GANs and VAEs share several commonalities:
- Generative Models: Generative models include both VAEs and GANs. This indicates that they pick up on the training data’s underlying distribution in order to produce fresh data points with comparable properties.
- Neural Network-Based: Neural networks serve as the foundation for both GANs and VAEs. Whereas VAEs are made up of an encoder and a decoder, GANs are made up of a generator and a discriminator.
- Utilization of Latent Space: The inputs of both models are mapped to a latent space with a lower dimension, from which outputs are derived. The data distribution can be investigated, changed, and comprehended using this latent space.
- Backpropagation and Gradient Descent: Gradient descent and backpropagation are used in the training of both GANs and VAEs. It is necessary to create a loss function and update the model’s parameters repeatedly in order to minimize this loss.
- Ability to Generate New Samples: New samples that weren’t included in the first training set can be produced by both GANs and VAEs. Though they can be applied to different kinds of data, these models are frequently employed to create images.
- Use of Non-linear Activation Functions: In order to represent complex data distributions, both models incorporate non-linear activation functions, such as ReLU, into their hidden layers.
Differences
Their differences lie in their training objectives and methodologies:
- Training Approach: GANs employ adversarial training to generate realistic data, while VAEs optimize data reconstruction within a probabilistic framework.
- Data Handling: VAEs are suited for handling noisy and incomplete data, making them ideal for financial modeling and anomaly detection, whereas GANs excel in creative content generation and image synthesis.
Lead the way in Generative Models with Q3 Technologies
Want to start the journey into the realm of generative models? Q3 Technologies can assist you. Our team of experts promises to take the best generative AI approach to make cutting-edge applications that enhance creativity and productivity.
Table of content
- Understanding Variational Autoencoders (VAEs)
- Advantages and Challenges of Variational Autoencoders
- Training Process for VAEs
- VAE Use Cases
- Exploring Generative Adversarial Networks (GANs)
- Advantages and Challenges of Generative Adversarial Networks
- Training Process for GANs
- GAN Use Cases
- Similarities and Differences

Explore More


Generative AI Services
How Generative AI Is Reshaping the Future

Generative AI